@article{dammu2026iagentbench,title={iAgentBench: Benchmarking Sensemaking Capabilities of Information-Seeking Agents on High-Traffic Topics},author={Dammu, Preetam Prabhu Srikar and Palkhiwala, Arnav and Roosta, Tanya and Shah, Chirag},journal={arXiv preprint arXiv:2603.04656},year={2026},url={https://arxiv.org/abs/2603.04656},}
ClaimDB: A Fact Verification Benchmark over Large Structured Data
Michael Theologitis, Preetam Prabhu Srikar Dammu, Chirag Shah, and 1 more author
@article{theologitis2026claimdb,title={ClaimDB: A Fact Verification Benchmark over Large Structured Data},author={Theologitis, Michael and Dammu, Preetam Prabhu Srikar and Shah, Chirag and Suciu, Dan},journal={arXiv preprint arXiv:2601.14698},year={2026},url={https://arxiv.org/abs/2601.14698},}
2025
Dynamic-KGQA: A Scalable Framework for Generating Adaptive Question Answering Datasets
Preetam Prabhu Srikar Dammu, Himanshu Naidu, and Chirag Shah
In 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2025), 2025
@inproceedings{dammu2025dynamickgqa,title={Dynamic-{KGQA}: A Scalable Framework for Generating Adaptive Question Answering Datasets},author={Dammu, Preetam Prabhu Srikar and Naidu, Himanshu and Shah, Chirag},booktitle={48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2025)},year={2025},url={https://dl.acm.org/doi/abs/10.1145/3726302.3730324},}
A Shopping Agent for Addressing Subjective Product Needs
Preetam Dammu, Omar Alonso, and Barbara Poblete
In Proceedings of the 18th ACM International Conference on Web Search and Data Mining (WSDM 2025), 2025
@inproceedings{dammu2025shopping,title={A Shopping Agent for Addressing Subjective Product Needs},author={Dammu, Preetam and Alonso, Omar and Poblete, Barbara},booktitle={Proceedings of the 18th ACM International Conference on Web Search and Data Mining (WSDM 2025)},year={2025},url={https://www.amazon.science/publications/a-shopping-agent-for-addressing-subjective-product-needs},}
2024
“They are uncultured”: Unveiling Covert Harms and Social Threats in LLM Generated Conversations
Preetam Prabhu Srikar Dammu, Hayoung Jung, Anjali Singh, and 2 more authors
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), 2024
@inproceedings{dammu2024uncultured,title={``They are uncultured'': Unveiling Covert Harms and Social Threats in {LLM} Generated Conversations},author={Dammu, Preetam Prabhu Srikar and Jung, Hayoung and Singh, Anjali and Choudhury, Monojit and Mitra, Tanushree},booktitle={Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024)},year={2024},url={https://arxiv.org/abs/2405.05378},}
ClaimVer: Explainable Claim-Level Verification and Evidence Attribution of Text Through Knowledge Graphs
Preetam Prabhu Srikar Dammu, Himanshu Naidu, Mouly Dewan, and 4 more authors
In Findings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024 Findings), 2024
@inproceedings{dammu2024claimver,title={ClaimVer: Explainable Claim-Level Verification and Evidence Attribution of Text Through Knowledge Graphs},author={Dammu, Preetam Prabhu Srikar and Naidu, Himanshu and Dewan, Mouly and Kim, YoungMin and Roosta, Tanya and Chadha, Aman and Shah, Chirag},booktitle={Findings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024 Findings)},year={2024},url={https://arxiv.org/abs/2403.09724},}
2023
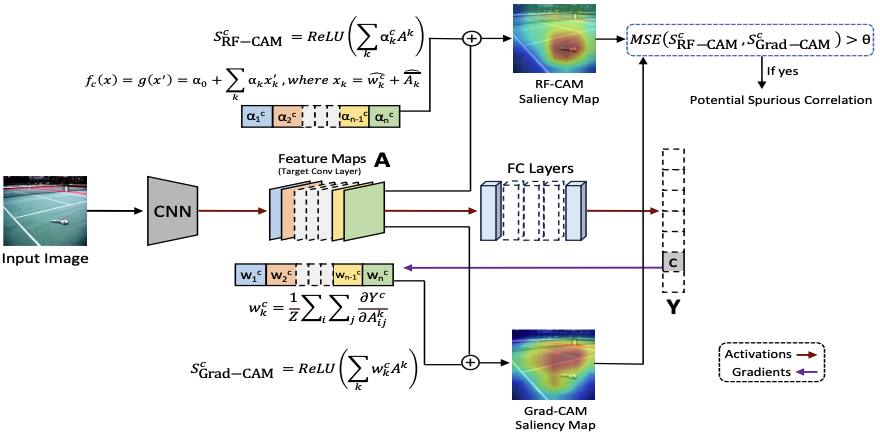
Detecting Spurious Correlations via Robust Visual Concepts in Real and AI-Generated Image Classification
Preetam Prabhu Srikar Dammu, and Chirag Shah
In 37th Conference on Neural Information Processing Systems (NeurIPS), XAIA Workshop, 2023
@inproceedings{dammu2023detecting,title={Detecting Spurious Correlations via Robust Visual Concepts in Real and {AI}-Generated Image Classification},author={Dammu, Preetam Prabhu Srikar and Shah, Chirag},booktitle={37th Conference on Neural Information Processing Systems (NeurIPS), XAIA Workshop},year={2023},url={https://openreview.net/forum?id=ewagDhIy8Y},}
Addressing Weak Decision Boundaries in Image Classification by Leveraging Web Search and Generative Models
Preetam Prabhu Srikar Dammu, Yunhe Feng, and Chirag Shah
In International Joint Conference on Artificial Intelligence, 2023
@inproceedings{Dammu2023AddressingWD,title={Addressing Weak Decision Boundaries in Image Classification by Leveraging Web Search and Generative Models},author={Dammu, Preetam Prabhu Srikar and Feng, Yunhe and Shah, Chirag},booktitle={International Joint Conference on Artificial Intelligence},year={2023},url={https://www.ijcai.org/proceedings/2023/659},}
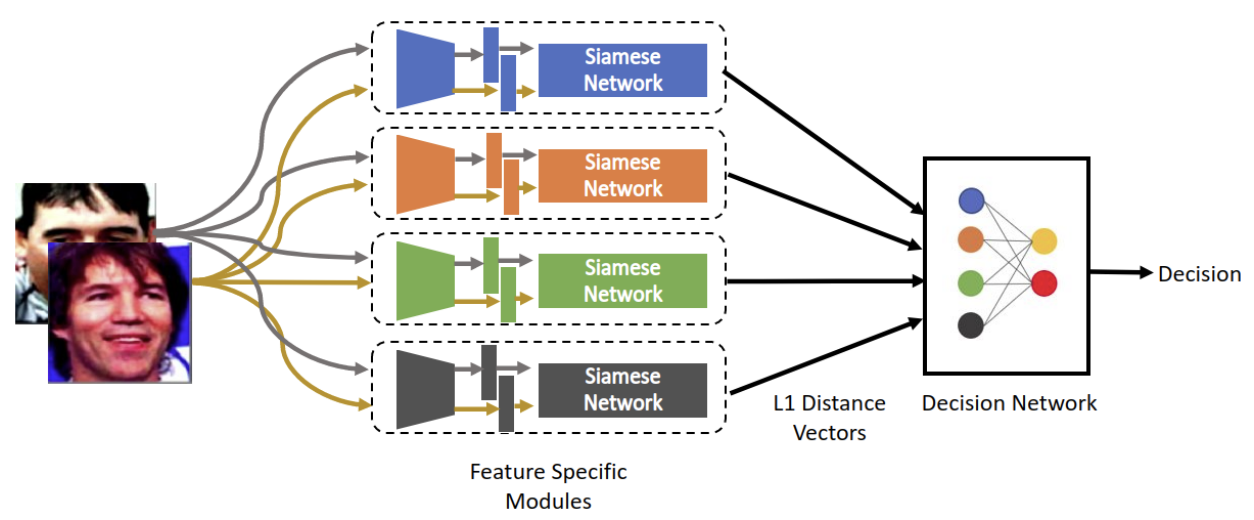
@inproceedings{dammu2021interpretable,title={Interpretable and Robust Face Verification.},author={Dammu, Preetam Prabhu Srikar and Chalamala, Srinivasa Rao and Singh, Ajeet Kumar and Yegnanarayana, Bayya},booktitle={CIKM Workshops},year={2021},}
2019
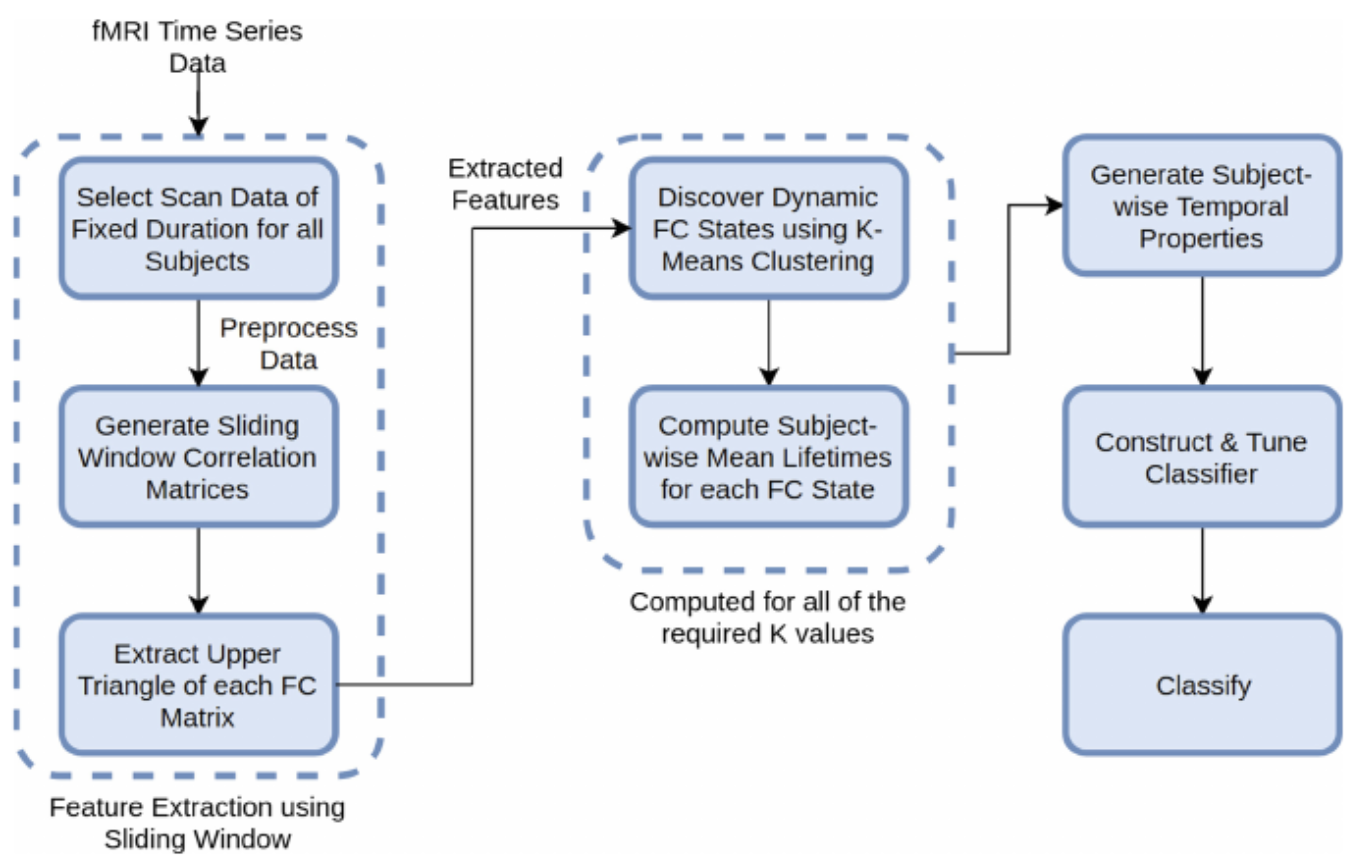
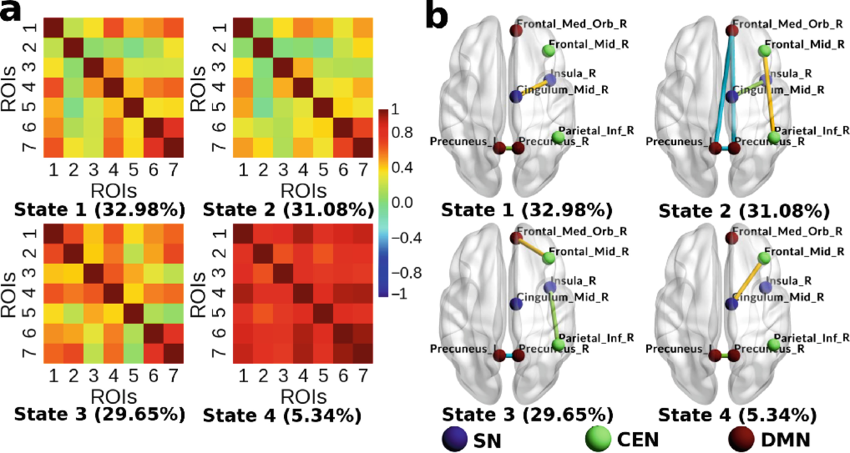
Employing temporal properties of brain activity for classifying autism using machine learning
Preetam Srikar Dammu, and Raju Surampudi Bapi
In Pattern Recognition and Machine Intelligence, 2019
@inproceedings{dammu2019employing,title={Employing temporal properties of brain activity for classifying autism using machine learning},author={Dammu, Preetam Srikar and Bapi, Raju Surampudi},booktitle={Pattern Recognition and Machine Intelligence},pages={193--200},year={2019},organization={Springer},}
Temporal dynamics of the brain using variational bayes hidden Markov models: application in autism
Preetam Srikar Dammu, and Raju Surampudi Bapi
In Pattern Recognition and Machine Intelligence, 2019
@inproceedings{dammu2019temporal,title={Temporal dynamics of the brain using variational bayes hidden Markov models: application in autism},author={Dammu, Preetam Srikar and Bapi, Raju Surampudi},booktitle={Pattern Recognition and Machine Intelligence},pages={121--130},year={2019},organization={Springer},}